Data science is a new area, but it is becoming more and more vital. It is the newest buzzword in the IT industry, and market demand for it has been constantly rising. Because businesses need to turn data into insights, there is a growing demand for data scientists. Google, Amazon, Microsoft, and Apple are some of the organizations that hire the most data scientists. Additionally, data science is growing in popularity among IT specialists.
According to a recent analysis by Precedence Research, the demand for Data Science is predicted to increase at a CAGR (Compound Annual Growth Rate) of 16.43 percent and attain the market value of a whopping 378.7 Billion over the projection period 2022 to 2030.
So, what exactly is Data Science, and why is it trending today? Let’s read further to understand more about Data Science.
A brief definition of Data Science
To discover the hidden actionable insights in an organization’s data, data scientists mix math and statistics, specialized programming, sophisticated analytics, artificial intelligence (AI), and machine learning with specialized subject matter expertise. Strategic planning and decision-making can be guided by these findings.
Data science is one of the fields with the quickest growth rates across all industries as a result of the increasing volume of data sources and data that results from them. Organizations are currently drowning in data. By combining numerous techniques, technologies, and tools, data science will assist in deriving insightful conclusions from that. Businesses encounter vast amounts of data in the areas of e-commerce, finance, medical, human resources, etc. They process them all with the use of technology and methods from data science. As a result, it is not surprising that Harvard Business Review named the position of data scientist the “sexiest job of the 21st century”. They are relied upon more and more by organizations to analyze data and make practical suggestions to enhance business results.
History of Data Science
Early in the 1960s, a new profession that would enable the understanding and analysis of the massive volumes of data that were being gathered at the time was given the name “Data Science.” (At the time, it was impossible to foresee the truly enormous volumes of data that would be generated over the next 50 years.) Data Science is a discipline that is constantly developing, employing computer science and statistical methods to acquire insights and generate valuable predictions in a variety of industries. In addition to being employed in fields like astronomy and health, data science is also used in business to aid in decision-making.
What is Data Science used for?
Data science has numerous applications across various industries and domains. Some of the common uses of data science include:
- Business Intelligence and Decision Making: Data science is used to examine big datasets and find patterns, trends, and correlations that can assist organizations in making well-informed decisions, maximizing operations, and enhancing overall effectiveness.
- Predictive Analytics: Data science models can be used to foresee future patterns and consequences, including consumer behavior, sales forecasting, equipment failure, and market movements, allowing firms to make strategic plans.
- Machine Learning and AI: The creation and application of machine learning and artificial intelligence models that can automate processes, spot trends, and make predictions are based on data science..
- Customer analytics: Data science enables companies to better understand the requirements, tastes, and behaviors of their customers, resulting in more individualized and focused marketing tactics.
- Healthcare and Medical Research: Data science plays a crucial role in analyzing medical data, identifying disease patterns, drug discovery, and developing personalized treatment plans.
- Finance and Banking: Data science is widely employed in consumer segmentation, algorithmic trading, fraud detection, credit risk assessment, and financial forecasting.
- Recommendation Systems: Data science underpins webpages’ recommendation engines, which give customers individualized recommendations for products or information.
- Social Media Analysis: To comprehend public opinion, conduct market research, and spot new trends, data science techniques are used to evaluate social media data, sentiment analysis, and user activity.
- Logistics and transportation: Data science enables better demand forecasting, route optimization, and overall operational efficiency.
- Environmental Science: Climate modeling, environmental monitoring, and natural catastrophe prediction all involve data science.
- Analytics in sports: Data science is used to study player performance, create game plans, and enhance team performance.
Data Science lifecycle
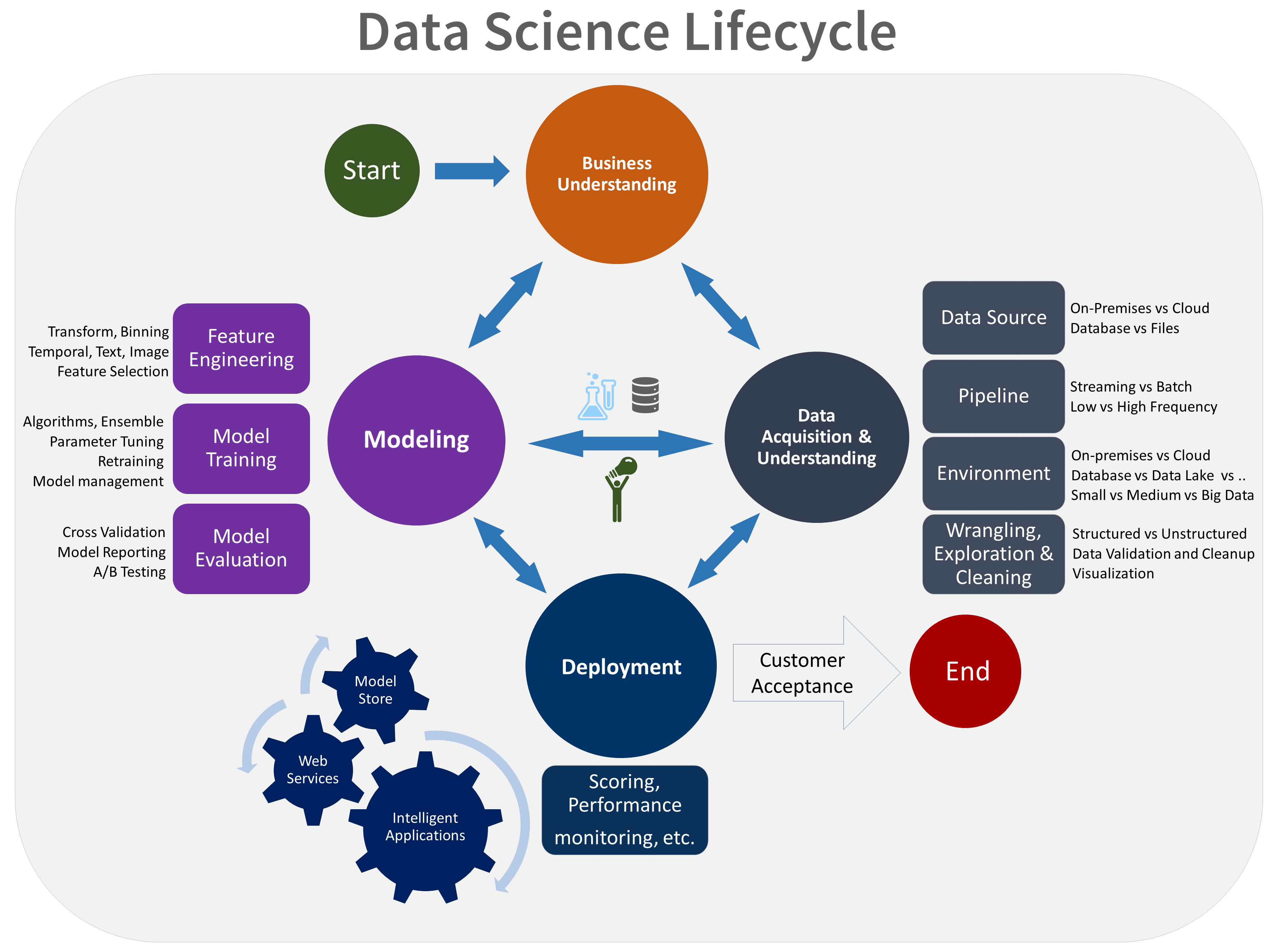
You can utilize the suggested lifecycle provided by Microsoft’s Team Data Science Process (TDSP) to organize your data-science initiatives. The entire process that successful projects adhere to is laid out in the lifespan.
This lifecycle is meant for data-science initiatives that are going to be released as components of smart applications. For predictive analytics, these apps use machine learning or artificial intelligence algorithms. The application of this technique can be advantageous for initiatives involving exploratory data science and improvised analytics. However, some of the method given here may not be necessary for certain projects..
1. Business Analysis
Defining the important variables that will serve as the model targets and whose associated metrics will be utilized to assess the project’s success is the final goal of this stage. There will also be an identification of the relevant data sources the company has access to or needs to get.
The two main tasks involved in this stage are:
- Define the goals: To understand and recognize the business issues, work with the client and other interested parties. Write down the business objectives that the data science techniques can address in your queries.
- Determine the data sources: Gather the relevant information that will assist you in providing answers to the questions that define the project’s goals.
2. Data acquisition and understanding
The objective of this project is to create a clear, high-quality data set with a clear understanding of how it relates to the target variables. The data set will be placed in the proper analytics setting and be prepared for modeling. Also, a solution architecture for the data pipeline that will routinely update and score the data will be created.
The steps involved in this project are as follows:
- Ingest the data into the target analytic environment.
- Explore the data to determine if the data quality is adequate to answer the question.
- Set up a data pipeline to score new or regularly refreshed data.
3. Modeling
In this step, the best data characteristics are chosen for the machine learning model, the most accurate predictions of the target are made, and a machine learning model that can be used in production is created.
The three main tasks involved in this stage are:
- Create data features from the raw data to make model training easier using feature engineering. In order to achieve this, the most important features must be chosen, converted into a format that the model can understand, and scaled so that they have a comparable range of values.
- Model training: Compare the models’ success metrics to see which one responds to the question the most accurately. In order to do this, many models must be trained on the data and their performance must be assessed using a holdout dataset. Then, the model that performs the best is chosen.
- Check to see if your model can be produced: This involves assessing the model’s performance using a range of metrics, including recall, accuracy, and precision. The model’s capacity to generalize to new data is also evaluated.
4. Deployment
Deploy models with a data pipeline to a production or production-like environment for final user acceptance.
Operationalizing the model is the primary task addressed in this phase: The model and pipeline should be delivered to a production environment or one that is similar for application consumption. Once you have a group of effective models, you can operationalize them so that other programs can use them. Predictions are made either in real time or in batches, depending on the business requirements. Models must be exposed with an open API interface in order to be deployed. The model may be simply consumed from a variety of applications thanks to the interface.
5. Customer acceptance
This phase’s objectives are to complete the project deliverables and validate that the pipeline, the model, and their deployment in a live environment meet the needs of the client. There are two primary tasks at this stage:
- System validation: Verify that the pipeline and deployed model satisfy the requirements of the customer. Working with the client to make sure the system satisfies their business requirements and provides questions with sufficient accuracy is necessary to do this.
- Project hand-off: Transfer the project to the organization in charge of running the system in production. This entails completing all of the paperwork and making sure the system is prepared for deployment in a real-world setting.
What does Data Scientist do?
A data scientist’s duties can change based on the industry, business, and project they are working on. According to U.S Bureau Labor of Statistic, here is a rough outline of the duties and abilities expected of a data scientist:
- Determine which data are available and useful for the project
- Collect, categorize, and analyze data
- Create, validate, test, and update algorithms and models
- Use data visualization software to present findings
- Make business recommendations to stakeholders based on data analysis
Data scientists gather relevant data sources, such as surveys, using web-scraping tools or databases. They start with unstructured datasets and clean or restructure them for accurate analysis by computer algorithms.
Data scientists create models and algorithms for machine learning systems, classifying and anticipating data, and ensuring accuracy through regular updates and data upgrades.
Data scientists utilize visualization software to present findings as charts, maps, and graphics, enabling clear communication to technical and nontechnical audiences, aiding in decision-making and process changes.
Data scientists specialize in specific fields, such as coding, engineering, web-browsing, research, and business strategy, focusing on systems, machine learning algorithms, and user engagement.
How to work in Data Science
Working in data science requires a combination of education, technical skills, practical experience, and a passion for solving complex problems using data. Here is some requirement ti get started in a data science career, according to U.S Bureau Labor of Statistic :
1. Educational Background:
Obtain a solid education in a relevant discipline, such as engineering, computer science, statistics, or another quantitative topic. The minimum need is a bachelor’s degree, although additional degrees (master’s or Ph.D.) in data science or similar subjects can provide you an advantage.
2. Other Experience:
Some employers demand education or experience relevant to the business. For instance, data scientists looking for work in the asset management sector might need to have prior experience in the finance sector or to have finished coursework showing a knowledge of banking, investing, or related topics.
3. Important Qualities
- Analytical skills: Data scientists need to be skilled in conducting research, reviewing, and interpreting results.
- Computer skills: Coders, data analysts, algorithm developers, and users of data visualization tools are all skills that data scientists must possess.
- Communication skills: To offer business suggestions, data scientists must be able to explain the findings of their analysis to both technical and nontechnical audiences.
- Logical-thinking skills: Data scientists must understand and be able to design and develop statistical models and to analyze data.
- Math skills: Data scientists gather and arrange data using statistical techniques.
- Problem-solving skills: Data scientists must come up with answers to the issues they run into when gathering and cleaning data, as well as when creating statistical models and algorithms.